EFK 日志管理系统实施方案与实操指南
1. 方案原理、架构与实现思路
1.1 EFK原理讲解
最开始,大家习惯直接登录服务器,靠 tail -f、grep 临时排查;但随着业务扩展,这种方式会越来越吃力:日志散落在多台机器上,异常堆栈被拆成多行,想按服务名、日志级别、线程名筛选几乎做不到,历史日志还会不断侵占磁盘空间。很多时候,真正拖慢排障效率的,不是问题有多复杂,而是日志根本不好查。
所以,日志系统要解决的,从来不只是“把文件收上来”,而是要完成从原始文本到结构化数据、从分散存储到统一检索、从临时排障到长期治理的升级。本文就结合实战,带你从 0 到 1 搭建一套基于 Elasticsearch、Fluent Bit 和 Kibana 的 EFK 日志管理系统,既讲原理,也讲落地。
EFK 正是这样一套经典方案:
Elasticsearch 负责存储与检索,Fluent Bit 负责采集与解析,Kibana 负责展示与分析。它的价值不只是把日志“集中起来”,更重要的是把原本分散、杂乱、难搜索的文本日志,变成可以按时间、级别、线程、类名、服务名等维度快速定位问题的结构化数据。本文就结合实际落地过程,完整介绍一套适合中小规模场景的 EFK 日志管理方案,包括架构设计、组件选型、部署配置、日志解析、多行合并、字段标准化以及常见问题排查,帮助你把“能看日志”真正升级为“会管理日志”
这套组合比较适合多台机器、多套服务的日志需要集中检索和统一管理的场景,能够满足按时间、日志级别、线程、类名、服务名等维度快速定位业务异常和系统问题的需求,同时可将访问日志、业务日志、错误日志等各类日志统一纳管,还能通过明确日志保存周期,避免磁盘被历史日志持续占满,有效解决日志管理的核心痛点。
1.2 采集器的选择
日志采集层是整个方案的“入口”,常见的采集工具包括Logstash、Filebeat和Fluent Bit,三者都能实现“将日志推送至Elasticsearch”的核心需求,但定位和侧重点各有不同,选择时需结合实际场景权衡;
Logstash的优势在于处理能力强、插件生态成熟,能完成复杂的ETL数据转换操作,但它本质是JVM程序,常驻内存和CPU占用较高,对于单机部署、边缘节点或普通业务机而言,仅为采集日志就部署Logstash会造成资源浪费,显得过于笨重;
Filebeat的优势是轻量、部署简单、稳定性强,更擅长标准化日志的转运工作,但它的解析能力相对薄弱,若遇到多种自定义日志格式、需要多组正则匹配、多行合并、字段重命名,或按文件名提取服务名等场景,单靠Filebeat往往无法完成全部处理,需将部分逻辑转移到Elasticsearch Ingest Pipeline或Logstash,导致链路变长、排查难度增加;
而Fluent Bit则处于一个均衡的定位,它的资源占用远低于Logstash,轻量高效,适合长期常驻在业务机上且不占用过多业务资源,同时解析能力比Filebeat更灵活,支持tail监听、多行合并、正则解析、Lua脚本扩展等功能,能应对多种复杂日志格式,对于“多种文本日志 + 统一字段规范 + 直接写入Elasticsearch”的核心场景,其功能足够实用,无需额外依赖其他组件,因此本文选择Fluent Bit,并非因为它功能最全面,而是它在资源占用、实时性、解析灵活度、部署复杂度之间达到了最佳平衡,是中小规模、自建式日志平台的最优解。
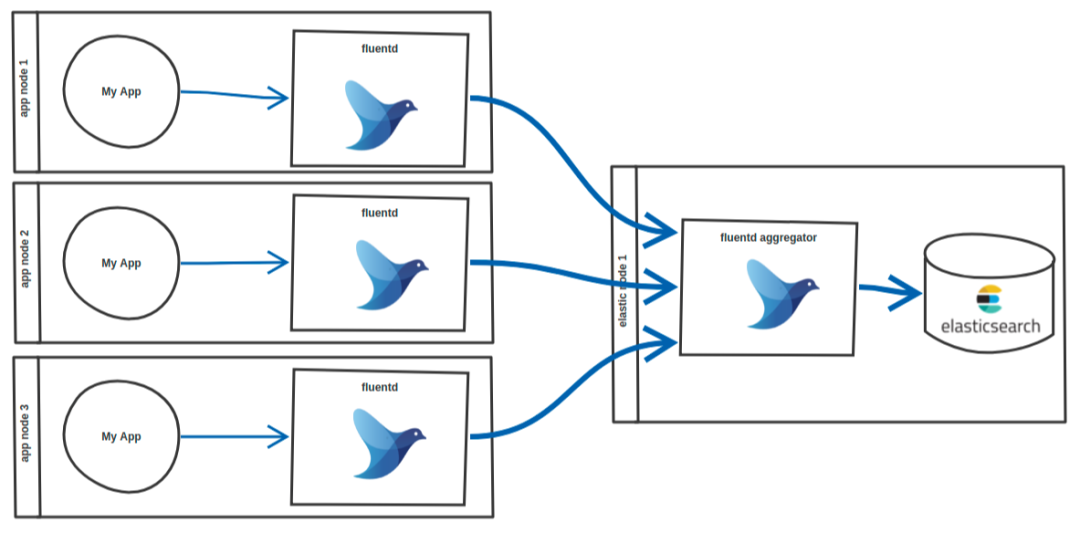
1.3 日志采集-存储-可视化流程
从数据流角度来看,EFK方案的逻辑并不复杂,但每一步都直接影响日志采集的稳定性和后续检索的便捷性,其完整流程连贯且环环相扣。
┌─────────────────────────────────────────────────────────────┐
│ 第一步:日志输出 │
│ 业务服务 → 按格式写入宿主机本地日志文件 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第二步:日志采集与多行合并 │
│ Fluent Bit(tail模式)→ 监听文件+记录偏移量 → 读取日志 → 合并 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第三步:日志结构化解析 │
│ parser解析器 → 提取时间/级别/线程名/类名/消息体等字段 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第四步:字段标准化与增强 │
│ Lua脚本 → 统一为ECS规范字段 → 补充主机名/服务名等缺失信息 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第五步:日志存储与生命周期管理 │
│ 写入Elasticsearch → 索引模板定义字段类型 → ILM控制保存周期 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第六步:日志可视化检索 │
│ Kibana → 检索/筛选/聚合统计/可视化展示 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 核心解决问题 │
│ 1. 多机日志集中统一管理 │
│ 2. 非结构化文本 → 结构化可检索数据 │
│ 3. 升级为长期可控、低成本、可扩展的日志系统 │
└─────────────────────────────────────────────────────────────┘从功能层面看,这是一套完整的日志采集与分析流程;但从工程实现角度,它本质上是在解决三个核心问题:一是将分散在多台业务机上的日志集中到一个平台进行统一管理,二是把非结构化的文本日志转换为可按字段检索的结构化数据,三是将日志平台从“临时工具”升级为可长期运行、可控成本、可持续扩展的系统。
1.4 组件职责
| 组件 | 作用 | 说明 |
|---|---|---|
| 业务服务 | 产生日志 | 以文件形式输出访问日志、业务日志、错误日志 |
| Fluent Bit Input | 采集日志 | 读取指定目录下的日志文件 |
| Fluent Bit Multiline | 合并多行 | 将异常堆栈等多行内容拼接为一条完整日志 |
| Fluent Bit Parser | 解析日志 | 从原始文本中拆出结构化字段 |
| Fluent Bit Lua | 标准化字段 | 统一字段命名,补充服务名、主机名等信息 |
| Elasticsearch | 存储检索 | 建立索引并支持按字段检索日志 |
| Kibana | 可视化分析 | 面向运维与开发查看日志、定位问题 |
1.5 设计原则
1.5.1 先采集,再结构化
很多团队一开始就希望应用日志直接输出成 JSON,这当然最好,但现实里历史服务、多框架、不同语言的日志格式往往并不统一。相比强行要求所有应用先改造日志格式,更务实的做法是:先把日志稳定采上来,再在采集侧完成统一解析和标准化。
这样做的好处是落地快、对业务侵入小,而且后续即使某个服务调整了日志格式,也只需要调整采集规则,不一定要改应用代码。
1.5.2 统一字段命名
Kibana 是否好用,很大程度上取决于字段是否统一。本文统一采用接近 ECS 风格的字段命名,例如:
@timestampservice.namehost.namelog.levellog.loggerthread.nameprocess.pidevent.datasetmessage
这样做的意义不只是“看起来规范”,更关键的是:后续不同服务接入时,查询语句、筛选条件、可视化图表和告警规则都可以复用。
1.5.3 采集侧做轻量处理
本文会把多行合并、文本解析、字段补充、字段重命名都放在 Fluent Bit 侧完成,而不是把所有处理都压到 ES 侧。原因很简单:
- 采集侧离日志源最近,问题更容易定位。
- 数据进入 ES 之前就已经结构化,后续检索体验更稳定。
- ES 负责存储和查询即可,不必额外承担过多前置清洗压力。
当然,极复杂的数据转换仍然可以交给 Logstash 或 Ingest Pipeline,但对本文这种“文本日志接入 + 标准字段落库”的场景,Fluent Bit 已经足够。
1.5.4 生命周期策略
日志平台与普通业务数据库最大的区别在于,日志数据是“持续增长型”数据,若没有明确的生命周期管理,日志会不断堆积,最终导致 Elasticsearch 磁盘被打满,或查询性能大幅下降。
因此,本文为所有业务日志索引(service-logs-*)配置了 ILM(索引生命周期管理)策略,例如设置日志仅保留 7 天,到期后自动删除。这一设计的重点,不是“节省磁盘空间”,而是从一开始就将日志平台作为长期运行的系统来规划,确保系统稳定性和可维护性。
1.5.5 单节点环境
本文默认的是单节点部署思路,因此索引会设置为:
- 主分片 1
- 副本 0
这样做不是为了偷懒,而是单节点环境本来就没有副本落点。此时继续保留副本只会让索引长期处于 yellow,并额外增加资源消耗。等后续扩展为多节点,再调整副本策略更合理。
2. ES 与 Kibana 部署
2.1 基础环境准备
Elasticsearch 对内核参数有要求,尤其是 vm.max_map_count。如果该值过小,ES 容器可能启动失败。
sudo sysctl -w vm.max_map_count=1048576
echo "vm.max_map_count=1048576" | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
mkdir -p /data/elk
sudo mkdir -p /data/elk/es-data /data/elk/kibana-data
# 推荐把目录所有者改成 1000,兼容 elastic/kibana 容器用户
sudo chown -R 1000:0 /data/elk/es-data /data/elk/kibana-data
# 确保容器用户具备读写权限
sudo chmod -R 775 /data/elk/es-data /data/elk/kibana-data2.2 docker-compose 配置
该文件用于启动 ES、初始化账户与角色,以及启动 Kibana。
version: "3.8"
services:
es01:
image: elasticsearch:9.3.1
container_name: es01
environment:
# 容器时区同步上海
- TZ=Asia/Shanghai
- node.name=es01
- cluster.name=elk-single
# 单节点集群模式
- discovery.type=single-node
- network.host=0.0.0.0
- http.port=9200
# 开启X-Pack安全认证
- xpack.security.enabled=true
# 关闭安全自动配置
- xpack.security.autoconfiguration.enabled=false
# 内网/测试环境关闭HTTP层SSL
- xpack.security.http.ssl.enabled=false
# 单节点关闭传输层SSL
- xpack.security.transport.ssl.enabled=false
# elastic超级用户密码
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
# JVM堆内存配置
- ES_JAVA_OPTS=-Xms${ES_HEAP} -Xmx${ES_HEAP}
# 安全限制:删除索引必须指定完整名称
- action.destructive_requires_name=true
# ES性能优化:解除内存锁定
ulimits:
memlock:
soft: -1
hard: -1
volumes:
# 同步宿主机时区到容器
- /etc/localtime:/etc/localtime:ro
# ES数据持久化(容器删除后数据不丢失)
- /data/elk/es-data:/usr/share/elasticsearch/data
ports:
# 宿主机端口映射
- "0.0.0.0:${ES_PORT:-9200}:9200"
# 健康检查:确保ES启动并认证正常后再启动依赖服务
healthcheck:
test: ["CMD-SHELL", "curl -sS -m 3 -u elastic:${ELASTIC_PASSWORD} http://127.0.0.1:9200/_security/_authenticate >/dev/null || exit 1"]
interval: 10s
timeout: 5s
retries: 60
# 重启策略:除非手动停止,否则异常自动重启
restart: unless-stopped
setup:
image: curlimages/curl:8.6.0
environment:
- TZ=Asia/Shanghai
- ES_URL=http://es01:9200
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- KIBANA_SYSTEM_PASSWORD=${KIBANA_SYSTEM_PASSWORD}
- LOG_INGEST_USER=${LOG_INGEST_USER}
- LOG_INGEST_PASSWORD=${LOG_INGEST_PASSWORD}
- KIBANA_VIEWER_USER=${KIBANA_VIEWER_USER}
- KIBANA_VIEWER_PASSWORD=${KIBANA_VIEWER_PASSWORD}
volumes:
- /etc/localtime:/etc/localtime:ro
# 挂载初始化脚本:用于创建自定义用户/角色
- /data/elk/setup.sh:/setup.sh:ro
# 执行初始化脚本(仅运行一次)
command: ["/bin/sh", "/setup.sh"]
# 重启策略:一次性执行,失败不重启
restart: "no"
# 依赖ES健康状态:避免脚本提前执行导致API调用失败
depends_on:
es01:
condition: service_healthy
kibana:
image: kibana:9.3.1
container_name: kibana
# 依赖ES健康状态:确保ES就绪后再启动Kibana
depends_on:
es01:
condition: service_healthy
environment:
- TZ=Asia/Shanghai
# Kibana界面设置为中文
- I18N_LOCALE=zh-CN
- SERVER_NAME=kibana
- SERVER_HOST=0.0.0.0
- ELASTICSEARCH_HOSTS=http://es01:9200
# Kibana专用连接用户
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=${KIBANA_SYSTEM_PASSWORD}
# 延长启动超时:避免ES未就绪导致Kibana启动失败
- ELASTICSEARCH_STARTUPTIMEOUT=300000
# Kibana加密密钥
- XPACK_SECURITY_ENCRYPTIONKEY=${KIBANA_ENC_KEY}
- XPACK_ENCRYPTEDSAVEDOBJECTS_ENCRYPTIONKEY=${KIBANA_SAVEDOBJ_KEY}
- XPACK_REPORTING_ENCRYPTIONKEY=${KIBANA_REPORT_KEY}
# 关闭非必要功能:减少资源占用+隐私保护
- TELEMETRY_ENABLED=false
- TELEMETRY_OPTIN=false
- NEWSFEED_ENABLED=false
- XPACK_FLEET_ENABLED=false
- XPACK_FLEET_AGENTS_ENABLED=false
volumes:
- /etc/localtime:/etc/localtime:ro
# Kibana数据持久化
- /data/elk/kibana-data:/usr/share/kibana/data
ports:
# 宿主机端口映射
- "0.0.0.0:${KIBANA_PORT:-5601}:5601"
restart: unless-stopped2.3 setup.sh 初始化脚本
该脚本负责完成以下动作:
- 等待 ES 服务就绪
- 启用并设置
kibana_system密码 - 创建日志写入角色
logs_writer - 创建日志读取角色
logs_reader - 创建采集器账户和 Kibana 查看账户
#!/bin/sh
set -eu
ES_URL="${ES_URL:-http://es01:9200}"
echo "[setup] ES_URL=${ES_URL}"
echo "[setup] wait ES auth..."
i=0
while true; do
i=$((i+1))
if curl -sS -m 3 -u "elastic:${ELASTIC_PASSWORD}" "${ES_URL}/_security/_authenticate" >/dev/null 2>&1; then
echo "[setup] ES auth OK"
break
fi
echo "[setup] retry=${i} (cannot reach ${ES_URL} yet)"
[ "$i" -ge 90 ] && echo "[setup] ERROR: timeout waiting ES" && exit 1
sleep 2
done
echo "[setup] enable kibana_system (ignore errors)..."
curl -sS -m 10 -u "elastic:${ELASTIC_PASSWORD}" -X PUT \
"${ES_URL}/_security/user/kibana_system/_enable" >/dev/null 2>&1 || true
echo "[setup] set kibana_system password..."
payload="$(printf '{"password":"%s"}' "${KIBANA_SYSTEM_PASSWORD}")"
curl -sS -m 10 -u "elastic:${ELASTIC_PASSWORD}" -X POST \
"${ES_URL}/_security/user/kibana_system/_password" \
-H "Content-Type: application/json" \
-d "${payload}" >/dev/null
echo "[setup] upsert roles..."
curl -sS -m 10 -u "elastic:${ELASTIC_PASSWORD}" -X PUT \
"${ES_URL}/_security/role/logs_writer" \
-H "Content-Type: application/json" \
-d '{"indices":[{"names":["service-logs-*"],"privileges":["auto_configure","create_index","create_doc","index","write"]}]}' >/dev/null
curl -sS -m 10 -u "elastic:${ELASTIC_PASSWORD}" -X PUT \
"${ES_URL}/_security/role/logs_reader" \
-H "Content-Type: application/json" \
-d '{"indices":[{"names":["service-logs-*"],"privileges":["read","view_index_metadata"]}]}' >/dev/null
echo "[setup] upsert users..."
payload="$(printf '{"password":"%s","roles":["logs_writer"]}' "${LOG_INGEST_PASSWORD}")"
curl -sS -m 10 -u "elastic:${ELASTIC_PASSWORD}" -X PUT \
"${ES_URL}/_security/user/${LOG_INGEST_USER}" \
-H "Content-Type: application/json" \
-d "${payload}" >/dev/null
viewer_role="viewer"
code="$(curl -s -m 5 -o /dev/null -w "%{http_code}" -u "elastic:${ELASTIC_PASSWORD}" "${ES_URL}/_security/role/viewer" || true)"
if [ "${code}" != "200" ]; then
viewer_role="kibana_admin"
fi
payload="$(printf '{"password":"%s","roles":["%s","logs_reader"]}' "${KIBANA_VIEWER_PASSWORD}" "${viewer_role}")"
curl -sS -m 10 -u "elastic:${ELASTIC_PASSWORD}" -X PUT \
"${ES_URL}/_security/user/${KIBANA_VIEWER_USER}" \
-H "Content-Type: application/json" \
-d "${payload}" >/dev/null
echo "[setup] DONE"2.4 环境变量配置
建议将环境变量单独放在 .env 文件中:
# 监听地址
ES_BIND_IP=0.0.0.0
KIBANA_BIND_IP=0.0.0.0
# 宿主机端口
ES_PORT=9200
KIBANA_PORT=5601
# ES heap
ES_HEAP=4g
# elastic 超级用户密码
ELASTIC_PASSWORD=elastic_super_password
# kibana_system 密码
KIBANA_SYSTEM_PASSWORD=kibana_system_password
# 写入 ES 的账号(采集器使用)
LOG_INGEST_USER=log_ingest
LOG_INGEST_PASSWORD=log_ingest_password
# Kibana 登录账号(只读)
KIBANA_VIEWER_USER=kibana_viewer
KIBANA_VIEWER_PASSWORD=kibana_viewer_password
# Kibana 固定加密 key(长度至少 32 位)
KIBANA_ENC_KEY=0123456789abcdef0123456789abcdef
KIBANA_SAVEDOBJ_KEY=abcdef0123456789abcdef0123456789
KIBANA_REPORT_KEY=00112233445566778899aabbccddeeff2.5 服务启动顺序
推荐启动顺序如下:
cd /data/elk
sysctl -w vm.max_map_count=262144
docker-compose down --remove-orphans
docker-compose up -d es01
docker-compose run --rm setup
docker-compose up -d kibana
docker-compose ps启动顺序的原因如下:
先启动 ES:因为后续初始化账户与角色依赖 ES 已正常提供认证服务。
再执行 setup:统一创建账号和角色,避免手动逐条执行命令。
最后启动 Kibana:Kibana 依赖 kibana_system 账户与密码已经初始化完成。
2.6 Elasticsearch 初始化策略
下面这些命令建议在已加载 .env 环境变量的前提下执行,避免把密码直接写进命令行。可先执行:
cd /data/elk
set -a
source ./.env
set +a除了账户和角色外,还应补充三类关键配置:
- 写入权限控制
- 读取权限控制
- 索引生命周期策略与索引模板
2.6.1 日志写入角色
仅允许 log_ingest 用户写入 service-logs-* 索引:
curl -u "elastic:${ELASTIC_PASSWORD}" -X PUT "http://127.0.0.1:9200/_security/role/logs_writer" \
-H "Content-Type: application/json" -d '{
"indices": [
{ "names": ["service-logs-*"], "privileges": ["auto_configure","create_index","create_doc","index","write"] }
]
}'2.6.2 日志读取角色
仅允许只读用户读取 service-logs-* 索引:
curl -u "elastic:${ELASTIC_PASSWORD}" -X PUT "http://127.0.0.1:9200/_security/role/logs_reader" \
-H "Content-Type: application/json" -d '{
"indices": [
{ "names": ["service-logs-*"], "privileges": ["read","view_index_metadata"] }
]
}'2.6.3 ILM 生命周期策略
创建日志生命周期策略,超过 7 天自动删除:
curl -u "elastic:${ELASTIC_PASSWORD}" -X PUT "http://127.0.0.1:9200/_ilm/policy/service-logs-7d" \
-H "Content-Type: application/json" -d '{
"policy": {
"phases": {
"hot": { "actions": {} },
"delete": { "min_age": "7d", "actions": { "delete": {} } }
}
}
}'2.6.4 索引模板
创建索引模板,确保所有 service-logs-* 索引默认具备统一配置:
curl -u "elastic:${ELASTIC_PASSWORD}" -X PUT "http://127.0.0.1:9200/_index_template/service-logs-template" \
-H "Content-Type: application/json" -d '{
"index_patterns": ["service-logs-*"],
"priority": 50,
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "service-logs-7d"
},
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"service.name": { "type": "keyword" },
"log.level": { "type": "keyword" },
"log.logger": { "type": "keyword" },
"thread.name": { "type": "keyword" },
"host.name": { "type": "keyword" },
"event.dataset": { "type": "keyword" }
}
}
}
}'2.6.5 为什么要定义模板
如果不定义模板,ES 会对新字段做动态映射,长期可能出现以下问题:
- 同一个字段在不同索引中被推断为不同类型
- 后续聚合分析、筛选排序出现异常
- 字段不规范,Kibana 检索体验变差
因此,建议对常用字段提前固定映射类型。
3. 采集侧部署与配置
3.1 Fluent Bit 安装
这里使用系统包安装,而不是再套一层容器,主要是因为采集器本身需要长期读取宿主机日志文件、管理 offset、通过 systemd 自启和排障。对日志采集器来说,离宿主机越近,部署和维护通常越直接。
在 Ubuntu 系统中可按如下方式安装:
# 1) 导入官方仓库 GPG key
sudo sh -c 'curl https://packages.fluentbit.io/fluentbit.key | gpg --dearmor > /usr/share/keyrings/fluentbit-keyring.gpg'
# 2) 添加 APT 源
codename=$(grep -oP "(?<=VERSION_CODENAME=).*" /etc/os-release 2>/dev/null || lsb_release -cs 2>/dev/null)
echo "deb [signed-by=/usr/share/keyrings/fluentbit-keyring.gpg] https://packages.fluentbit.io/ubuntu/$codename $codename main" \
| sudo tee /etc/apt/sources.list.d/fluent-bit.list
sudo apt-get update
sudo apt-get install -y fluent-bit
# 启动并设置开机自启
sudo systemctl enable --now fluent-bit3.2 初始化目录与 systemd 配置
sudo mkdir -p /var/lib/fluent-bit/storage
sudo chown -R root:root /etc/fluent-bit
sudo chmod 755 /var/lib/fluent-bit
sudo systemctl edit fluent-bit在编辑界面写入以下内容:
[Service]
EnvironmentFile=-/etc/fluent-bit/fluent-bit.env
Environment=TZ=Asia/Shanghai
ExecStart=
ExecStart=/opt/fluent-bit/bin/fluent-bit -c /etc/fluent-bit/fluent-bit.conf然后执行:
sudo systemctl daemon-reload这里这样做的目的有两个:
- 允许把 ES 地址、账号密码等变量放进单独的环境文件中,便于维护
- 显式指定 Fluent Bit 使用的主配置文件路径,避免系统默认路径不一致
4. 常见日志格式
在实操中,日志采集的核心难点不是“把文件读出来”,而是“把不同格式的日志正确解析成结构化字段”。下面列出本方案中支持的几种典型格式。
4.1 Java 标准首行格式
示例:
2026-03-04 15:21:39.027 INFO 3856551 --- [main] com.demo.OrderService : order created特点:
- 时间格式为
yyyy-MM-dd HH:mm:ss.SSS - 包含日志级别、进程号、线程名、类名和消息体
- 常见于 Spring Boot 默认日志格式
提取目标字段:
timelevelpidthreadloggermsg_head
4.2 Java ISO 时间 + service 标识 + 线程格式
示例:
2026-03-04T15:21:39.027+08:00 INFO 3856551 --- [service] [kafka-async-50] com.demo.TaskJob : async task start特点:
- 时间中带时区偏移
- 多了一层应用名或服务名标识
- 适合从日志中直接提取应用维度信息
提取目标字段:
timelevelpidappthreadloggermsg_head
4.3 Java thread-dash 格式
示例:
2026-03-04 15:21:39.027 [http-nio-8080-exec-1] INFO com.demo.UserController - query user success特点:
- 常见于 Logback 自定义格式
- 线程名在前,日志级别和类名跟在后面
- 消息通过
-分隔
提取目标字段:
timethreadlevelloggermsg_head
4.4 Go 制表符分隔格式
示例:
2026-03-04T15:21:39.027+0800 INFO order.consumer order consumed successfully特点:
- 以制表符分隔字段
- 常见于 Go 服务自定义日志输出
- 时间带时区偏移
提取目标字段:
timelevelloggermsg_head
4.5 多行解析
有些日志并不是一行就结束,例如 Java 异常:
2026-03-04 15:21:39.027 ERROR 3856551 --- [main] com.demo.OrderService : submit failed
java.lang.RuntimeException: order failed
at com.demo.OrderService.create(OrderService.java:35)
at com.demo.OrderController.submit(OrderController.java:18)如果不做多行合并,异常堆栈会被拆成多条无意义日志,后续查询时难以定位真实错误。因此 Fluent Bit 中必须配置 multiline 规则,把异常堆栈与首行日志合并为一条完整记录。
5. Fluent Bit 核心配置
5.1 主配置文件 /etc/fluent-bit/fluent-bit.conf
[SERVICE]
Flush 1
Daemon Off
Log_Level info
Parsers_File /etc/fluent-bit/parsers.conf
Parsers_File /etc/fluent-bit/multiline_parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
storage.path /var/lib/fluent-bit/storage
storage.sync normal
storage.checksum off
storage.max_chunks_up 256
[INPUT]
Name tail
Tag service.app
Path /data/logs/service-*.log
Key message
Exclude_Path *.gz,*.zip,*.tmp
Refresh_Interval 2
Rotate_Wait 10
DB /var/lib/fluent-bit/tail_service_all.db
Mem_Buf_Limit 256MB
Skip_Long_Lines On
storage.type filesystem
Read_From_Head Off
Path_Key log.file.path
Multiline.Parser service_java_ts
Buffer_Chunk_Size 256k
Buffer_Max_Size 8M
[FILTER]
Name lua
Match service.*
script /etc/fluent-bit/enrich.lua
call normalize_record
[FILTER]
Name parser
Match service.*
Key_Name message
Parser service_go_tab
Reserve_Data True
Preserve_Key True
[FILTER]
Name parser
Match service.*
Key_Name message
Parser service_java_iso_service
Reserve_Data True
Preserve_Key True
[FILTER]
Name parser
Match service.*
Key_Name message
Parser service_java_firstline
Reserve_Data True
Preserve_Key True
[FILTER]
Name parser
Match service.*
Key_Name message
Parser service_java_thread_dash
Reserve_Data True
Preserve_Key True
[FILTER]
Name lua
Match service.*
script /etc/fluent-bit/enrich.lua
call enrich_record
[OUTPUT]
Name es
Match service.*
Host ${ES_HOST}
Port ${ES_PORT}
HTTP_User ${ES_USER}
HTTP_Passwd ${ES_PASS}
Logstash_Format On
Logstash_Prefix service-logs
Logstash_DateFormat %Y.%m.%d
Time_Key @timestamp
Retry_Limit False
Suppress_Type_Name On
Generate_ID On
Buffer_Size 5M
Trace_Error On5.2 主配置执行顺序说明
Fluent Bit 配置不能只看“有哪些段”,更要看“这些段按什么顺序生效”。同样一套配置,顺序不同,效果可能完全不同。本文按实际数据流来解释:日志先被读取,再被标准化,再尝试解析,再继续增强,最后才输出到 ES。
这份配置虽然看起来只是若干段配置块,但在运行时其实有明确执行顺序。
5.2.1 SERVICE 段
[SERVICE] 是 Fluent Bit 的全局运行配置,主要控制以下内容:
Flush 1- 每 1 秒刷新一次输出,保证日志尽快写入 ES。
Log_Level info- 控制 Fluent Bit 自身日志级别,便于排查问题。
Parsers_File- 指定普通解析器和多行解析器配置文件。
HTTP_Server On- 开启 HTTP 监控接口,便于查看采集状态。
storage.path- 启用本地缓冲目录,用于应对 ES 暂时不可用等场景。
5.2.2 INPUT 段
[INPUT] 负责从文件中读取日志,核心项如下:
Name tail- 使用 tail 方式持续追踪文件新增内容。
Tag service.app- 为当前采集流量打标签,后续过滤器和输出器通过标签匹配。
Path /data/logs/service-*.log- 读取匹配该规则的所有日志文件。
Key message- 将每行日志原文写入
message字段。
- 将每行日志原文写入
Exclude_Path *.gz,*.zip,*.tmp- 忽略压缩文件和临时文件,避免重复采集。
Refresh_Interval 2- 每 2 秒刷新一次文件扫描。
Rotate_Wait 10- 日志轮转后等待 10 秒,减少轮转切换期间的丢日志风险。
DB /var/lib/fluent-bit/tail_service_all.db- 保存采集偏移量,实现断点续传。
Read_From_Head Off- 默认从文件末尾开始采集,避免首次启动就把历史大批量日志全部打入 ES。
Path_Key log.file.path- 把日志来源文件路径写入字段,后续可从路径中提取服务名。
Multiline.Parser service_java_ts- 启用多行合并规则,处理 Java 异常堆栈。
storage.type filesystem- 允许使用本地文件系统作为缓冲,提升稳健性。
5.2.3 第一段 Lua 过滤:标准化
先做标准化,而不是先上 parser,是为了先把颜色控制字符、历史遗留字段名、原始 log 字段这类噪音处理掉。这样后面的 parser 面对的是更干净的输入,规则更稳定,也更容易排错。
[FILTER]
Name lua
Match service.*
script /etc/fluent-bit/enrich.lua
call normalize_record这一步优先执行“规范化”操作,主要是为了在真正解析之前先把原始文本处理干净,例如:
- 去除 ANSI 颜色码
- 将历史字段
log迁移为message - 删除顶层
log字段,避免与 ES 中log.*对象字段冲突
5.2.4 Parser 过滤:依次匹配不同日志格式
这里连续配置了多个 parser:
service_go_tabservice_java_iso_serviceservice_java_firstlineservice_java_thread_dash
这么做的目的不是让一条日志同时命中所有规则,而是让 Fluent Bit 逐个尝试解析。只要某条日志格式匹配成功,就能提取出目标字段。这样可以在同一套采集配置中兼容多种日志输出格式。
5.2.5 第二段 Lua 过滤:字段增强
字段增强放在 parser 之后,是因为此时时间、级别、线程、logger 等核心字段已经被拆出来了,Lua 可以更从容地做字段重命名和补充。如果把这一步放到 ES Ingest Pipeline,当然也能做,但排查链路会更靠后;放在采集侧,问题通常更早暴露。
[FILTER]
Name lua
Match service.*
script /etc/fluent-bit/enrich.lua
call enrich_record这一步在日志已经被 parser 拆出字段后执行,主要做三类事情:
- 补充标准字段
- 将自定义字段改名为标准字段
- 删除无用中间字段
例如:
level->log.levellogger->log.loggerthread->thread.namepid->process.pid
同时还会根据日志文件名补充:
service.nameevent.dataset
5.2.6 OUTPUT 段
输出配置负责把解析后的日志写入 Elasticsearch:
Name es- 使用 ES 插件输出
Match service.*- 接收所有标签匹配
service.*的日志
- 接收所有标签匹配
Logstash_Format On- 自动按日期生成索引名
Logstash_Prefix service-logs- 最终索引名类似
service-logs-2026.03.18
- 最终索引名类似
Time_Key @timestamp- 使用
@timestamp作为时间字段
- 使用
Generate_ID On- 自动生成文档 ID
Retry_Limit False- 输出失败时持续重试,降低日志丢失风险
6. Fluent Bit 环境变量
6.1 /etc/fluent-bit/fluent-bit.env
ES_HOST=192.168.119.7
ES_PORT=9200
ES_USER=log_ingest
ES_PASS=log_ingest_password
NODE_NAME=prod这里的 ES_USER / ES_PASS 要与前文 .env 中创建的采集写入账号保持一致。本文统一约定:采集写入账号使用 log_ingest,对应密码使用 log_ingest_password。
6.2 变量说明
ES_HOST- Elasticsearch 地址
ES_PORT- Elasticsearch 端口
ES_USER- Fluent Bit 写入 ES 使用的账号
ES_PASS- Fluent Bit 写入 ES 使用的密码
NODE_NAME- 当前主机名称,最终写入
host.name
- 当前主机名称,最终写入
将环境变量与主配置文件分离,可以减少直接修改配置文件的频率,也方便在不同机器上复用同一份采集模板。
7. 日志解析器配置
7.1 /etc/fluent-bit/parsers.conf
[PARSER]
Name service_java_firstline
Format regex
Regex ^(?<time>\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}\.\d{3})\s+(?<level>[A-Z]+)\s+(?<pid>\d+)\s+---\s+\[(?<thread>[^\]]+)\]\s+(?<logger>[^:]+)\s+:\s*(?<msg_head>.*)
Time_Key time
Time_Format %Y-%m-%d %H:%M:%S.%L
Time_System_Timezone true
[PARSER]
Name service_java_iso_service
Format regex
Regex ^(?<time>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d{3})[+-]\d{2}:\d{2}\s+(?<level>[A-Z]+)\s+(?<pid>\d+)\s+---\s+\[(?<app>[^\]]+)\]\s+\[\s*(?<thread>[^\]]+)\]\s+(?<logger>[^:]+)\s+:\s*(?<msg_head>.*)
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_System_Timezone true
[PARSER]
Name service_java_thread_dash
Format regex
Regex ^(?<time>\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}\.\d{3})\s+\[(?<thread>[^\]]+)\]\s+(?<level>[A-Z]+)\s+(?<logger>\S+)\s+-\s+(?<msg_head>.*)$
Time_Key time
Time_Format %Y-%m-%d %H:%M:%S.%L
Time_System_Timezone true
[PARSER]
Name service_go_tab
Format regex
Regex ^(?<time>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d{3}[+-]\d{4})\t(?<level>[A-Z]+)\t(?<logger>[^\t]+)\t(?<msg_head>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z7.2 解析器设计说明
日志解析这一步决定了后续 Kibana 是否“好查”。解析失败,日志即使进了 ES,也常常只能全文搜字符串;解析成功,才能按级别、线程、类名、服务名等维度快速筛选。
7.2.1 多个 parser
日志格式在不同项目、不同语言、不同框架下往往不统一。将多个 parser 串联后,可以让同一个 Fluent Bit 实例兼容多个日志来源,而不必为每个服务单独部署一套采集程序。
这里不建议把所有格式硬拼成一个超长正则。表面上看是一份规则,实际上会让可读性、可维护性和排错体验都变差。拆成多个 parser,谁负责什么格式会更清楚,也更容易逐条验证。
7.2.2 Regex 中字段
以 service_java_firstline 为例:
time:日志时间level:日志级别pid:进程号thread:线程名logger:日志类名或 logger 名称msg_head:消息正文
这些字段解析出来之后,会在 Lua 阶段进一步转成统一字段名。
7.2.3 时间字段单独指定
日志时间如果不明确指定 Time_Key 和 Time_Format,Fluent Bit 可能无法正确识别日志时间,最终导致:
@timestamp不准确- Kibana 中日志时间排序异常
- 查询时间范围时出现偏差
因此每种日志格式都需要显式指定时间格式。
8. 多行解析配置
8.1 /etc/fluent-bit/multiline_parsers.conf
[MULTILINE_PARSER]
Name service_java_ts
Type regex
Flush_Timeout 3000
Rule "start_state" "/^\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}\.\d{3}\s+/" "cont"
Rule "cont" "/^(?!\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}\.\d{3}\s+).*/" "cont"8.2 规则说明
多行规则最好放在采集器侧处理,而不是等日志进 ES 之后再“猜哪些行属于同一条记录”。因为一旦拆散入库,异常堆栈和 SQL 片段在检索时就已经失去上下文了,后补往往成本更高。
该规则的含义如下:
- 只要一行以标准时间开头,就认定它是一条新日志的起始行
- 后续所有“不以时间开头”的行,都视为当前日志的续行
- 直到再次遇到新的时间开头行,才结束上一条日志
这正适用于 Java 异常堆栈、多行 SQL、长文本错误信息等场景。
9. 字段增强脚本
9.1 /etc/fluent-bit/enrich.lua
-- /etc/fluent-bit/enrich.lua
function normalize_record(tag, ts, record)
local msg = record["message"]
if msg ~= nil then
msg = string.gsub(msg, "\27%[[0-9;]*m", "")
record["message"] = msg
end
if record["message"] == nil and record["log"] ~= nil then
record["message"] = record["log"]
end
if record["log"] ~= nil then
record["log"] = nil
end
return 1, ts, record
end
function enrich_record(tag, ts, record)
local path = record["log.file.path"]
if path ~= nil then
local name = string.match(path, "/([^/]+)%.log")
if name ~= nil then
record["service.name"] = name
record["event.dataset"] = name
end
end
local hn = os.getenv("NODE_NAME")
if hn ~= nil then
record["host.name"] = hn
end
if record["level"] ~= nil then
record["log.level"] = record["level"]
record["level"] = nil
end
if record["logger"] ~= nil then
record["log.logger"] = record["logger"]
record["logger"] = nil
end
if record["thread"] ~= nil then
record["thread.name"] = record["thread"]
record["thread"] = nil
end
if record["pid"] ~= nil then
record["process.pid"] = record["pid"]
record["pid"] = nil
end
record["msg_head"] = nil
record["time"] = nil
return 1, ts, record
end9.2 脚本逻辑说明
Lua 在这里承担的是“轻量增强”角色,而不是把 Fluent Bit 写成脚本平台。它最适合做字段整理、变量补充、命名统一这类小而明确的工作;复杂业务逻辑依然不建议堆到采集器里。
9.2.1 normalize_record
该函数用于“清洗原始日志”,主要完成:
- 去除颜色控制字符
- 将旧字段
log统一迁移到message - 删除 ES 易冲突字段
log
这个步骤必须放在解析前执行,否则 parser 可能拿到的是带颜色码或字段混乱的内容。
9.2.2 enrich_record
该函数用于“补充标准字段”,主要完成:
- 从文件名中提取服务名,写入
service.name - 从环境变量中写入
host.name - 将非标准字段重命名为标准字段
- 删除中间字段,减少无用数据入库
这一步做完之后,日志会从“原始文本”变成“结构化日志记录”,后续在 Kibana 中检索会更方便。
10. 启动与验收
10.1 启动 Fluent Bit
sudo systemctl daemon-reload
sudo systemctl restart fluent-bit
sudo systemctl status fluent-bit10.2 验证采集进程是否正常
先看服务状态:
systemctl status fluent-bit
journalctl -u fluent-bit -f10.3 验证 ES 是否收到日志
curl -u "${LOG_INGEST_USER}:${LOG_INGEST_PASSWORD}" "http://127.0.0.1:9200/_cat/indices?v"查看是否已经生成类似索引:
service-logs-2026.03.18也可以进一步抽样查看数据:
curl -u "elastic:${ELASTIC_PASSWORD}" "http://127.0.0.1:9200/service-logs-*/_search?pretty" -H "Content-Type: application/json" -d '{
"size": 5,
"sort": [
{ "@timestamp": "desc" }
]
}'10.4 Kibana 侧验证建议
进入 Kibana 后,建议检查以下内容:
- 是否能看到
service-logs-*索引 - 是否存在
@timestamp字段 - 是否能按以下字段筛选:
service.namelog.levellog.loggerthread.namehost.name
- 一条 Java 异常堆栈是否已经被合并为单条日志
11. 常见问题排查
11.1 ES 启动失败
问题现象:ES 容器无法启动、启动后立即退出,或健康检查一直失败。
核心检查项:系统内核参数、数据目录权限、容器内存、采集账户配置。
分步排查逻辑:
- 检查
vm.max_map_count内核参数:执行sysctl vm.max_map_count,若结果小于 262144(ES 最低要求),需临时+永久生效配置:sudo sysctl -w vm.max_map_count=262144 && echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf && sudo sysctl -p。 - 校验数据目录权限:执行
ls -ld /data/elk/es-data,确保目录所有者为 1000:0(ES 容器默认运行用户),权限为 775;若不符,执行sudo chown -R 1000:0 /data/elk/es-data && sudo chmod -R 775 /data/elk/es-data。 - 排查容器内存资源:执行
docker stats es01,查看容器可用内存是否低于 ES 堆内存配置(ES_HEAP),若内存不足,调整docker-compose.yml中容器内存限制,或降低ES_HEAP数值(建议不超过宿主机物理内存的 1/2)。 - 核对采集账户与环境变量:执行
cat /data/elk/.env,确认ELASTIC_PASSWORD、LOG_INGEST_USER/LOG_INGEST_PASSWORD配置正确,且启动脚本已加载该文件(source ./.env)。
11.2 Fluent Bit 服务启动失败
问题现象:Fluent Bit 服务无法启动、启动后报错退出,或 systemd 服务状态异常(systemctl status fluent-bit 显示 failed)。
核心检查项:配置文件路径、依赖文件存在性、配置拼写、systemd 覆盖配置。
分步排查逻辑:
- 校验主配置文件路径:执行
ls /etc/fluent-bit/fluent-bit.conf,确认文件存在;若不存在,检查 systemd 配置中-c参数是否指向正确路径(/etc/fluent-bit/fluent-bit.conf)。 - 检查依赖文件完整性:确认
parsers.conf、multiline_parsers.conf(路径在Parsers_File配置中)、enrich.lua脚本是否存在于/etc/fluent-bit/目录,缺失则补回模板文件。 - 排查配置拼写错误:执行
fluent-bit -c /etc/fluent-bit/fluent-bit.conf -v,通过 verbose 模式启动,直接输出配置语法错误(如字段名拼错、缩进错误),逐行修正。 - 核对 systemd 覆盖配置:执行
systemctl cat fluent-bit,查看ExecStart路径是否为/opt/fluent-bit/bin/fluent-bit -c /etc/fluent-bit/fluent-bit.conf,若被自定义修改,恢复标准配置后重新加载:sudo systemctl daemon-reload && sudo systemctl restart fluent-bit。
11.3 日志文件存在但未采集到
问题现象:业务日志目录有文件,但 Fluent Bit 采集目录(/var/log/fluent-bit/)无输出,ES 中无对应索引文档。
核心检查项:采集路径配置、文件权限、排除规则、采集偏移量、采集模式。
分步排查逻辑:
- 核对
Path采集路径:检查fluent-bit.conf中[INPUT]段的Path配置(如/data/logs/service-*.log),确保路径与日志实际存储目录一致,支持通配符但无拼写错误。 - 校验日志文件权限:执行
ls -l /data/logs/,确认日志文件权限允许 Fluent Bit 进程读取(至少 644 权限),若为只读或属主不符,执行sudo chmod 644 /data/logs/*.log && sudo chown -R root:root /data/logs。 - 排查
Exclude_Path排除规则:检查配置中Exclude_Path是否误包含目标文件(如将.log排除为.gz),若有误,删除对应排除规则或调整排除范围。 - 检查采集偏移量与模式:确认
Read_From_Head配置为Off(仅采集新增日志),若需采集历史日志,临时改为On;同时删除采集 DB 文件(/var/lib/fluent-bit/tail_service_all.db),清理旧偏移量后重启服务:sudo rm -f /var/lib/fluent-bit/tail_service_all.db && sudo systemctl restart fluent-bit。
11.4 日志入 ES 但字段不完整
问题现象:ES 中存在日志文档,但缺少 service.name、log.level、thread.name 等核心字段,或字段值为空/错误。
核心检查项:parser 匹配规则、多行解析规则、Lua 脚本逻辑。
分步排查逻辑:
- 校验 parser 匹配规则:执行
cat /etc/fluent-bit/parsers.conf,确认对应日志格式(如 Java 标准格式、Go 制表符格式)的 parser 正则表达式正确,且[FILTER] parser段的Parser字段与日志格式匹配。 - 调整多行解析规则:检查
multiline_parsers.conf中Multiline_Start/Multiline_End规则是否过宽(误合并无关日志)或过窄(未合并完整异常堆栈),针对 Java 异常场景,优化规则为“以时间戳开头为新日志行,以at开头为堆栈行”。 - 排查 Lua 脚本逻辑:执行
cat /etc/fluent-bit/enrich.lua,检查normalize_record/enrich_record函数是否误删除核心字段,或字段赋值逻辑错误(如将host.name赋值为空),修正脚本后重启 Fluent Bit。
11.5 Kibana 查不到日志
问题现象:Kibana 检索界面无数据,或筛选后显示“No results found”。
核心检查项:时间范围、索引模式、时间字段、ES 索引文档。
分步排查逻辑:
- 校准时间范围:Kibana 检索时,将时间范围调整为“最近 15 分钟/1 小时”,避免因时间范围过窄(如仅选未来时间)导致无数据。
- 核对索引模式:进入 Kibana「Stack Management」→「Index Patterns」,确认索引模式为
service-logs-*,且与 ES 中实际索引名称(service-logs-年.月.日)完全匹配。 - 校验
@timestamp字段:执行curl -u 弹性账号:密码 -X GET "http://ES地址:9200/service-logs-*/_search?size=1&pretty",查看返回结果中是否存在@timestamp字段,且为合法时间格式,若缺失,检查 Fluent Bit 中Time_Key配置是否为@timestamp。 - 验证 ES 索引文档:执行上述 ES 搜索命令,确认返回结果中存在
hits数组(即有文档),若无数据,回溯至“日志文件存在但未采集到”的排查步骤,重新检查 Fluent Bit 采集配置。
13. 总结
从表面上看,EFK 只是把日志从业务机器采集到 Elasticsearch,再交给 Kibana 做查询展示;但从工程价值上看,它解决的其实是日志管理里最核心的几个问题:日志不再分散、排障不再依赖人工翻文件、字段不再混乱不可检索、存储也不再无限增长失控。
更重要的是,这套方案并不只是一次性的“搭环境”。当你完成采集、解析、标准化、生命周期管理这些基础能力后,日志系统就从被动排查工具,变成了可以长期支撑运维、开发和问题追踪的基础设施。后续无论是接入更多服务、扩展更多日志格式,还是继续往告警、监控、可视化分析方向演进,都会建立在这套统一的基础之上。
如果你当前也正面临“日志分散难查、异常定位慢、历史日志难管理”这些问题,那么这套 EFK 实施方案,值得尽快落地。因为真正高效的日志系统,从来不只是“把日志存下来”,而是让日志能够在问题发生时,第一时间给出答案。
评论