[TOC]
最近搞了一个轻量型的服务器,由于是小厂,所以价格上很优惠,但是买完了之后,我人蒙了:
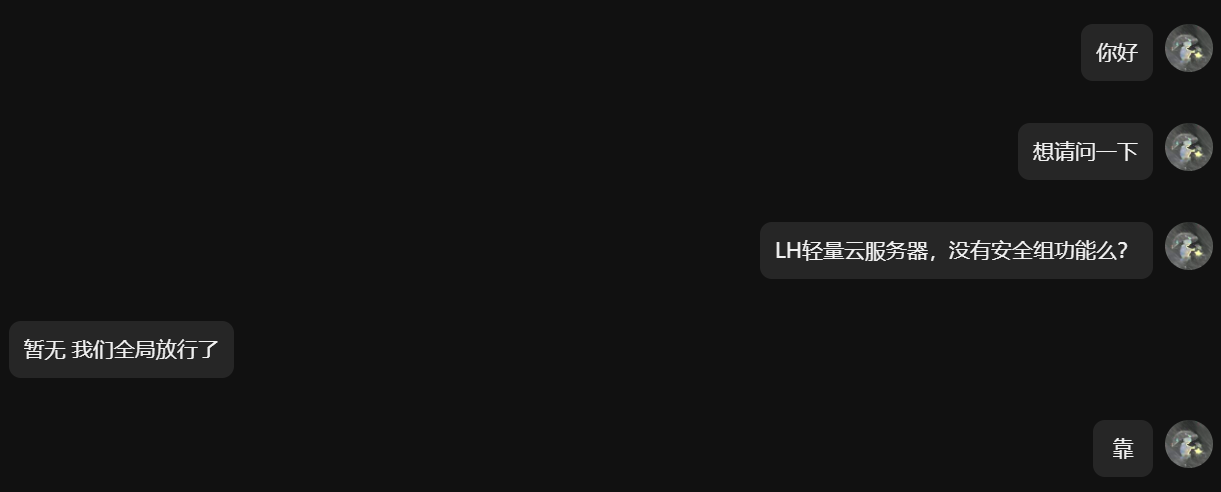
服务器的物理网卡直接绑定的公网IP、没有安全组、没有内网IP,那我说白了,这个小厂的轻量服务器的网络架构,就是把服务器网线直接绑死公网 IP,中间没搞 NAT 转换,也没加一层防火墙、交换机做防护,直接把服务器怼到公网里了。
等于就是少了路由器、少了交换机、少了防火墙这几层,公网流量直接跑到服务器网卡上,服务器自己拿着公网 IP 直面全网,没有任何中间设备帮你挡一下,纯纯裸奔接入公网。
仔细想想,我也不会防火墙啊,也不是说不会,对于防火墙整体性设计还不是很懂,但是你说那也不能直接用,如果遇到端口扫描、ssh暴力破解,我服务器连端口限制都没有,让人随便打了,**宴请八方?**所以了解了一下防火墙的相关内容,决定不使用Iptables,去使用nftables,具体原因,我们往下讲。
一、nftables介绍
1.1 nftables理解
nftables内核引擎为Linux内核添加了一个简单的虚拟机,能够执行字节码来检查网络数据包并决定如何处理该数据包。该虚拟机实现的操作被刻意设计得基础化,它能够从数据包本身获取数据,查看关联的元数据(例如入站接口),并管理连接跟踪数据。基于这些数据,可使用算术运算符、位运算符和比较运算符进行决策。该虚拟机还支持操作数据集合(通常为IP地址),从而能用单次集合查询替代多次比较操作。
怎么更简单的去理解呢?
简单来说,nftables 的核心就是 Linux 内核里的这个迷你虚拟机,我们通过表、链、规则这类简洁语法编写防火墙策略,告诉这个内核虚拟机:哪些流量可以进出、哪些 IP 允许访问、哪些端口开放、哪些流量直接拦截,这套语法就是我给虚拟机下达的指令,虚拟机收到后会自动按照我的规则处理所有网络数据包。
1.2 iptables与nftables对比
nftables 与 iptables 核心横向对比:
| 对比维度 | iptables | nftables |
|---|---|---|
| 核心架构 | 传统四表五链固定架构,多模块独立 | 内核级迷你虚拟机架构,统一灵活 |
| 协议支持 | 分裂管理:iptables (IPv4)、ip6tables (IPv6)、独立工具 | 统一管理:单配置支持 IPv4/IPv6/ARP/ 网桥 |
| 语法风格 | 命令行参数式,记忆难、冗余多 | 声明式简洁语法,可读性高、易编写 |
| 规则匹配 | 线性遍历匹配,规则越多速度越慢 | 哈希 / 红黑树查询,万条规则无性能衰减 |
| 规则更新 | 全量重载规则,高并发易闪断、丢连接 | 原子增量更新,热修改无中断、无损耗 |
| 动态集合 | 依赖第三方 ipset,配置繁琐 | 原生支持 IP / 端口集合,一键增删改查 |
| Docker 兼容 | 需兼容层,规则混乱、性能一般 | 原生适配,网络转发 / NAT 完美支持 |
| 兼容性 | 老旧系统全兼容,新系统逐步弃用 | 新系统原生支持,提供 iptables 兼容层 |
| 维护状态 | 停止新功能开发,仅维护修复 | 官方主推、持续更新、Linux 未来标准 |
更主要的原因是我使用的ubuntu22.04系统出厂默认就自带nftables,无需安装更多插件,系统原生适配,并且当规则变多的时候,也不会增加CPU使用负担,多方考虑决定学习并使用nftables。
1.3 nftables工作流程
┌─────────────────────────────────────────────────────────────┐
│ 第一步:数据包入站 │
│ 网络数据包抵达Linux内核网络栈 → 进入Netfilter框架处理流程 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌──────────────────────────────────────────────────────────────────┐
│ 第二步:钩子触发 │
│ 内核按流量路径触发钩子 → prerouting/input/forward/output/postrouting │
└───────────────────────────┬──────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第三步:内核虚拟机启动 │
│ nftables内核引擎加载 → 初始化字节码运行环境 → 加载规则集 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第四步:规则匹配检索 │
│ 按表/链优先级遍历 → 提取数据包IP/端口/接口/状态等元数据 │
│ 支持集合/哈希高效匹配 → 替代传统逐条线性比对 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第五步:逻辑决策执行 │
│ 执行算术/位运算/比较运算 → 匹配规则定义的过滤/转发/NAT策略 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第六步:动作处理 │
│ 执行最终动作 → ACCEPT放行/DROP丢弃/REJECT拒绝/NAT地址转换 │
│ 原子化操作无中断 → 支持增量更新规则集 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 第七步:流量出站 │
│ 处理完成的数据包离开内核网络栈 → 转发至目标地址/本机应用/公网 │
└───────────────────────────┬─────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 核心解决问题 │
│ 1. 统一管理IPv4/IPv6/网桥/ARP全协议栈防火墙规则 │
│ 2. 高性能数据包匹配,规则量越大优势越明显 │
│ 3. 灵活自定义过滤逻辑,替代老旧iptables固定架构 │
│ 4. 原子更新、无中断热修改,适配生产环境动态规则调整 │
└─────────────────────────────────────────────────────────────┘网络数据包抵达 Linux 内核网络栈后,会进入 Netfilter 框架并触发对应的钩子节点,nftables 内核虚拟机随之启动,加载配置好的规则集与字节码执行环境。虚拟机从数据包中提取 IP 地址、端口、入站接口、连接状态等核心数据,结合算术、位运算和比较逻辑,在定义好的表和链中执行规则匹配,利用哈希、集合等高效数据结构替代传统线性遍历,快速完成流量匹配判断。
完成匹配后,虚拟机将执行规则中定义的动作,包括放行、丢弃、拒绝、网络地址转换等,处理后的数据包按照决策结果离开内核网络栈,转发至本机应用、目标主机或公网。整个过程支持原子化的规则更新与热修改,无需中断网络服务,同时统一覆盖 IPv4、IPv6、网桥等多种网络场景,实现灵活且高性能的网络流量管控。
二、nftables使用
为了简化理解、提升使用效率,我选择不深入讲解表、链、规则等底层概念,而是从实际操作和应用场景出发,让我们快速掌握 nftables 的核心用法,更好地理解并落地使用。并且,我们更多选择以配置文件的方式进行配置,而不是更多以命令的方式。
更加详细使用请参考相关文档:
2.0 配置文件格式
我们先来了解一下配置文件格式,ubuntu系统默认出厂就会给一个nftables配置文件,在/etc/nftables.conf 路径之下,我们查看一下这个配置文件:
root@tencent:~# cat /etc/nftables.conf
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
# 入向
chain input {
type filter hook input priority 0;
}
# 转发
chain forward {
type filter hook forward priority 0;
}
# 出向
chain output {
type filter hook output priority 0;
}
}第一行:#!/usr/sbin/nft -f,这是配置文件的固定声明,作用是告诉操作系统:“请使用 nftables 工具来执行这个文件”。
flush ruleset:作用是清空系统中所有旧的防火墙规则,避免新旧规则冲突、导致异常,这也是配置文件的固定开头,每次加载配置都会先清空,再加载新规则。
table inet filter{}:这是 nftables 的核心规则容器,我们所有的防火墙规则(放行、拦截、端口限制等),都写在这个大括号 { } 里面。
chain input:专门管理进入服务器的流量(别人访问你的服务器)。后面我们要加的 SSH 白名单、放行业务端口、拦截恶意流量,全都写在这个 input 链里。
chain forward:专门管理转发流量(服务器中转的流量)。如果你使用 Docker 容器、搭建网关,就需要配置这里,默认是空的。
chain output:专门管理服务器主动发出的流量(服务器访问外网、下载软件、发送数据)。默认没有任何限制,服务器可以自由访问外部网络。
**内部的 type filter hook ... priority 0:**这是链的核心三要素——type 指定链的类型(如过滤、NAT),hook 指定流量经过的钩子节点,priority 控制执行优先级。初学者保留默认值即可,后面我们还会遇到不同的组合方式。
小知识:
priority 0和priority filter是完全等价的,filter只是0的别名写法,后面章节中我们统一使用更具可读性的priority filter。
总结三个部分:
-
我想访问别人(本机发起):走 output。
-
别人想访问我(访问本机服务):走 input。
-
别人通过我访问别人(路由转发):走 forward。
所以在初始状态下,Ubuntu 默认的这个配置文件,没有任何拦截 / 放行规则,相当于:
-
✅ 所有流量都可以进入服务器
-
✅ 所有流量都可以转发
-
✅ 所有流量都可以发出
简单说:默认配置 = 服务器裸奔在公网,没有任何防护。一般情况下,云服务器会有安全组,但是我们也讲了,我们现在不是一般情况,hhh,无奈之举让自己学了一点新东西。
这也是我们接下来要一步步修改、加固配置的原因。
2.1 基础安全加固
这是服务器防火墙的核心安全底座,也是我们必须最先配置的内容。Ubuntu 默认的 nftables 是完全放开所有流量的,等于服务器在公网裸奔。
基础安全加固的作用:默认拒绝所有外部流量,只放行系统正常运行必需的流量,从根源上堵住安全漏洞。
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
# policy drop:拒绝所有进入服务器的流量
type filter hook input priority filter;policy drop;
# 放行本地回环接口,本机内部访问
iif "lo" accept
# 放行已建立连接和关联连接
ct state established,related accept
# 丢弃无效、恶意的数据包
ct state invalid drop
}
chain forward {
type filter hook forward priority 0;
}
chain output {
type filter hook output priority 0;
}
}policy drop:最关键的一句,默认拒绝所有进入服务器的流量。没有被我们特意放行的流量,全部拦截,这是安全的核心。
iif "lo" accept:放行本机自己访问自己的流量(比如程序调用本地服务),系统必需,不能删。
ct state established,related accept:放行服务器主动对外请求后,外界返回的流量(比如你用服务器下载软件,服务器能收到回包)。
ct state invalid drop:自动丢弃非法、畸形、攻击类的数据包,简单防御基础网络攻击。
配置效果
配置完成后,你的服务器立刻从「裸奔模式」变成「安全锁闭模式」:
- 所有陌生流量无法进入服务器
- 系统正常运行不受任何影响
- 为后续 SSH 白名单、端口放行打下安全基础
核心配置内容:
chain input {
type filter hook input priority filter; policy drop;
# 放行本地回环接口
iif "lo" accept
# 放行已建立连接和关联连接(服务器对外回复的流量)
ct state established,related accept
# 丢弃无效、恶意的数据包
ct state invalid drop
}如果你不想修改配置文件,只想临时生效这条基础安全规则(服务器重启后会失效),可以直接执行以下命令;想要永久保留规则,依然推荐使用配置文件方式。
# 设置默认策略:拒绝所有入站流量(注意:policy 不是规则,需要用专用命令设置)
nft chain inet filter input '{ policy drop; }'
# 放行本地回环接口
nft add rule inet filter input iif "lo" accept
# 放行已建立连接和关联连接
nft add rule inet filter input ct state established,related accept
# 丢弃无效、恶意的数据包
nft add rule inet filter input ct state invalid drop在这里我就不展示直接应用本配置后的效果了,因为这是一台公网云服务器。如果现在直接加载这套基础安全规则,会因为默认拦截所有入站流量,导致我的 SSH 连接立刻断开,无法再操作服务器。
等后面讲解完成 2.2 SSH IP 白名单 之后,我会统一演示如何完整配置并正确应用 nftables 规则,保证安全的同时不会断开服务器连接。
2.2 SSH IP白名单
基础安全加固完成后,服务器已经默认拒绝所有入站流量,接下来我们要做的就是开放 SSH 权限,但不是开放给所有人,而是只允许你信任的 IP 登录。这是公网服务器最重要的安全配置之一,能彻底防止 SSH 暴力破解。
我们在 input 链中添加以下规则,替换成你自己的 IP 即可:
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
# policy drop:拒绝所有进入服务器的流量
type filter hook input priority filter;policy drop;
# 放行本地回环接口,本机内部访问
iif "lo" accept
# 放行已建立连接和关联连接
ct state established,related accept
# 丢弃无效、恶意的数据包
ct state invalid drop
# 仅允许指定IP地址访问SSH
ip saddr { 192.168.0.0/24 , 1.2.3.4 } tcp dport 22 accept
}
chain forward {
type filter hook forward priority 0;
}
chain output {
type filter hook output priority 0;
}
}核心就是增添一条:
# 仅允许指定 IP 访问 SSH(22 端口)
ip saddr { 192.168.0.0/24, 1.2.3.4 } tcp dport 22 accept配置说明
ip saddr { ... }:只允许这些 IP 访问tcp dport 22:目标端口是 SSH(22)accept:允许通过
如何修改成你的 IP:把示例里的 IP 换成你自己的办公 IP、家庭 IP、常用外网 IP 即可。多个 IP 用逗号分隔,格式固定为 { IP1, IP2, IP3 }。
如果使用命令添加,执行下面这条命令:
nft add rule inet filter input ip saddr { 192.168.0.0/24, 1.2.3.4 } tcp dport 22 accept这回我们就可以执行规则的应用了,执行以下命令进行规则的使用:
nft -f /etc/nftables.conf-f 参数代表从指定配置文件加载规则,执行后所有配置立即生效。执行后没有任何弹出显示,就代表我们的规则配置正确,反之就要检查我们编写的规则语法是否存在问题进行修改。
查看已经生效的规则:
nft list ruleset 执行之后就能查看到已经生效的规则:
table inet filter {
chain input {
type filter hook input priority filter; policy drop;
iif "lo" accept
ct state established,related accept
ct state invalid drop
ip saddr { 192.168.0.0/24, 1.2.3.4 } tcp dport 22 accept
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}list ruleset 是 nftables 专用的查看命令,执行后会完整输出我们配置的基础安全规则、SSH IP 白名单等所有已生效规则,方便我们核对配置是否准确。
如果使用iptables,推荐搭配Fail2ban,也可以实现ssh防火墙效果
2.3 命令添加规则方式
顺便来讲一下命令添加规则的方式,我们把这条规则拆成 4 个部分,它们是**「并且」的关系**——必须同时满足所有条件,才会放行流量,缺一不可。nftables 命令行添加规则,有固定的万能组合格式:
nft add rule [表名称] [链名称] [条件1] [条件2] [最终动作]我以添加ssh这条规则作为示例:
nft add rule:固定开头 → 代表向 nftables 里添加一条规则
inet filter:固定表名 → 我们配置文件里的 table inet filter
input:固定链名 → 代表「入站流量规则」
ip saddr { 你的IP }:条件 1 → 来源 IP 必须是白名单里的 IP
tcp dport 22:条件 2 → 目标端口必须是 22
accept:最终动作 → 满足所有条件,放行流量
组合 1:只加一个条件,仅放行 IP
nft add rule inet filter input ip saddr { 192.168.1.1 } accept含义:这个 IP 发来的所有流量,全部放行
组合 2:再加一个条件(IP + 端口)
nft add rule inet filter input ip saddr { 192.168.1.1 } tcp dport 22 accept含义:只有这个 IP,访问 22 端口,才放行(我们的 SSH 规则)
组合 3:再加一个条件(IP + 端口 + 新连接)
nft add rule inet filter input ip saddr { 192.168.1.1 } tcp dport 22 ct state new accept含义:仅允许这个 IP 新建 22 端口连接,更安全
同样的道理,删除规则方式。但这里有一个重要区别:推荐使用 handle 号(规则的唯一编号)来删除规则,这种方式最安全、不会误删。虽然 nftables 也支持按条件删除,但 handle 方式更精准,是生产环境的推荐做法。
先使用 -a 参数查看每条规则的 handle 编号:
nft -a list ruleset输出中每条规则后面都会带有 # handle 数字,找到你要删除的规则编号,执行删除:
nft delete rule [表名称] [链名称] handle [编号]
# 示例:删除 inet filter 表 input 链中 handle 编号为 10 的规则
nft delete rule inet filter input handle 102.4 放行业务端口
经过基础安全加固和 SSH 白名单配置后,服务器默认拦截了所有外部入站流量,我们的网站、应用程序等业务服务自然也无法被外部访问。
解决这个问题的核心方法,就是放行业务服务对应的端口,让外部流量可以正常访问我们的服务。同时,我们还可以结合 IP 限制,实现更精细化的流量管控。将以下规则添加到/etc/nftables.conf的input链中,根据你的业务端口进行修改:
# 放行单一业务端口
tcp dport 3000 accept
# 放行多个业务端口
tcp dport { 80 , 443 , 3000 , 8080 } accept单个端口:直接修改数字即可,例如将3000替换为你的服务端口;
多个端口:使用大括号包裹,端口间用英文逗号分隔,格式固定为{ 端口1, 端口2 };
协议说明:我们示例中使用tcp协议,适用于绝大多数 Web 服务、应用服务。
当然这里有个小细节:
执行规则进行查看:
$ nft list ruleset
table inet filter {
chain input {
# ......
# 单个端口
tcp dport 3000 accept
# 多个端口
tcp dport { 80, 443, 8080 } accept
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}如果需要限制仅指定 IP可以访问业务端口,我们可以组合 IP 和端口条件,实现精细化管控,这是生产环境常用的安全策略:
# 仅允许指定IP访问80/443端口
ip saddr { 1.2.3.4, 192.168.0.0/24 } tcp dport { 80, 443 } accept
# 查看规则
table inet filter {
chain input {
# ...
tcp dport 3000 accept
tcp dport { 80, 443, 8080 } accept
ip saddr { 1.2.3.4, 192.168.0.0/24 } tcp dport { 80, 443 } accept
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}那么问题来了:
tcp dport { 80, 443, 8080 } accept
ip saddr { 1.2.3.4, 192.168.0.0/24 } tcp dport { 80, 443 } accept前面允许了所有IP访问80、443端口,下面又配置了特定的IP才能访问80、443端口,这个策略到底听谁的呢?
用一句话总结:
nftables 规则是 从上到下 逐行匹配的,只要匹配到了第一条符合条件的规则,立刻执行动作,后面的所有规则直接跳过、不再看!
所以这两条规则,只有一条生效了:任何 IP 访问 80/443 端口,立刻匹配到规则 1 直接执行 accept 放行,规则 2 完全不会被执行,等于白写。
So,这也就诞生了规则的相关管控:严格规则放上面,宽松规则放下面。
2.5 Docker 网络兼容配置
在配置好 nftables 防火墙后,如果你直接启动 Docker 容器,有概率会遇到容器无法启动、端口映射失败、网络报错的问题,我先给大家看一个真实的启动报错:
docker run -d --name nginxpulse \
-p 8088:8088 \
-v ./docker_local/logs:/share/logs:ro \
-v ./docker_local/nginxpulse_data:/app/var/nginxpulse_data \
-v ./docker_local/pgdata:/app/var/pgdata \
-v ./docker_local/configs:/app/configs \
-v /etc/localtime:/etc/localtime:ro \
magiccoders/nginxpulse:latest
3d43009c5bcc16053915f71d1983bfe57a6b8e4267d7e51eec00bbed667d8cdb
docker: Error response from daemon: failed to set up container networking: driver failed programming external connectivity on endpoint nginxpulse (586d37fbd055569b34d46eb43514bcade4182c5c21e75344fb9ae3b7dcd1f9a3): Unable to enable DNAT rule: (iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 8088 -j DNAT --to-destination 172.17.0.3:8088 ! -i docker0: iptables: No chain/target/match by that name.
(exit status 1))
Run 'docker run --help' for more information为什么会出现这个错误?
这是 Docker + nftables 最常见的兼容问题:
我们的防火墙默认禁止了所有流量转发,而 Docker 运行必须依赖流量转发才能实现端口映射、容器联网、容器间通信;Docker 需要自动创建网络地址转换(NAT)规则,没有防火墙放行权限,就会直接创建失败;
简单说:防火墙拦住了 Docker 的网络请求,导致容器无法启动。想要正常使用 Docker,我们必须在 nftables 中添加专属的网络兼容规则。整体配置:
# 转发链
chain forward {
type filter hook forward priority filter; policy drop;
# 允许外部流量通过端口映射访问Docker容器(新连接)
iifname != "docker0" oifname "docker0" ct state new accept
# 允许外部网络回复的流量,进入Docker容器
oifname "docker0" ip daddr 172.17.0.0/16 ct state established,related accept
# 允许Docker容器主动发出的流量,访问外部网络
iifname "docker0" ip saddr 172.17.0.0/16 accept
}
# NAT 规则表(Docker 端口映射、联网核心配置)
table inet nat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
oifname != "docker0" ip saddr 172.17.0.0/16 ip daddr != 127.0.0.0/8 masquerade
}
chain DOCKER {
type nat hook prerouting priority dstnat; policy accept;
}
chain DOCKER_OUTPUT {
type nat hook output priority -100; policy accept;
}
}我们先来讲解转发部分内容:
# 允许外部流量通过端口映射访问Docker容器(新连接)
iifname != "docker0" oifname "docker0" ct state new accept
# 允许外部网络回复的流量,进入Docker容器
oifname "docker0" ip daddr 172.17.0.0/16 ct state established,related accept
# 允许Docker容器主动发出的流量,访问外部网络
iifname "docker0" ip saddr 172.17.0.0/16 accept字段配置:
oifname:流量要出去的网卡名称(output interface name)iifname:流量进来的网卡名称(input interface name)"docker0":Docker 自动创建的虚拟网卡,所有容器都通过它联网ip daddr:流量的目标 IP 地址(destination address)172.17.0.0/16:Docker 容器默认的内部局域网 IP 段,注意相关网段进行修改ct state established,related:外部服务器返回的正常响应流量ct state new:新建连接,用于放行外部通过端口映射主动访问容器的流量accept:放行
为什么需要
ct state new这条规则? Docker 通过 DNAT(目标地址转换)实现端口映射,外部访问宿主机映射端口时,流量会被转发到容器内部。如果 forward 链没有放行这类新连接,policy drop会先丢弃数据包,导致端口映射失败。这条规则确保外部流量能正常到达容器。
总结:forward 链做了三件事——①放行外部主动访问容器的端口映射流量(新连接),②放行外部服务回复给容器的响应流量(已建立连接),③放行容器主动发出的所有出站流量。
下面讲解NAT 规则表:
# NAT 规则表:专门管「网络地址转换」,Docker 联网、端口映射全靠它
table inet nat {
# 出口转发规则:容器访问外网的核心
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
# IP 伪装:让Docker容器可以正常访问互联网(排除回环地址)
oifname != "docker0" ip saddr 172.17.0.0/16 ip daddr != 127.0.0.0/8 masquerade
}
# 以下两条是 Docker 内置固定规则
# Docker 端口映射必需的系统链
chain DOCKER {
type nat hook prerouting priority dstnat; policy accept;
}
# Docker 内部网络转发必需链
chain DOCKER_OUTPUT {
type nat hook output priority -100; policy accept;
}
}table inet nat
这是全新的规则表,和之前的 filter 表分工不同:
filter表:管放行 / 拦截nat表:管容器上网、端口映射,没有它 Docker 完全无法工作;
chain postrouting:它是流量出门检查站。所有Docker 容器想访问外网的流量,都必须经过这里。
oifname != "docker0":流量不是发给 Docker 内部的(要出公网的)
ip saddr 172.17.0.0/16:流量来源是 Docker 容器内部网段
ip daddr != 127.0.0.0/8:排除目标为回环地址的流量,避免容器访问本机 127.0.0.1 时被错误伪装
masquerade(IP 伪装):Docker 容器没有独立公网 IP,靠这个规则共享服务器的网络上网;
DOCKER / DOCKER_OUTPUT:这是 Docker 自己要求的固定系统链,必须原样写,是端口映射的底层支撑。
So,容器想访问外网时,把容器的内部 IP,伪装成服务器的公网 IP。加上
ip daddr != 127.0.0.0/8是为了确保容器访问宿主机本地服务时走正常路径,不被伪装规则干扰。
这个部分可能会有点绕,我也花了好长时间理解,总结就使用下面的模版:
#!/usr/sbin/nft -f
flush ruleset
# 防火墙核心过滤规则表
table inet filter {
# 入站流量规则
chain input {
type filter hook input priority filter; policy drop;
}
# docker核心转发部分
chain forward {
type filter hook forward priority filter; policy drop;
# 放行外部通过端口映射访问容器的新连接
iifname != "docker0" oifname "docker0" ct state new accept
oifname "docker0" ip daddr 172.17.0.0/16 ct state established,related accept
iifname "docker0" ip saddr 172.17.0.0/16 accept
}
chain output {
type filter hook output priority filter; policy accept;
}
}
# Docker NAT 网络规则
table inet nat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
oifname != "docker0" ip saddr 172.17.0.0/16 ip daddr != 127.0.0.0/8 masquerade
}
chain DOCKER {
type nat hook prerouting priority dstnat; policy accept;
}
chain DOCKER_OUTPUT {
type nat hook output priority -100; policy accept;
}
}配置加载完成后,我们执行 nft list ruleset 命令,重启Docker后就能看到服务器所有生效的防火墙规则,以下是真实运行效果展示(这里仅加载了 Docker 兼容模版做演示,input 链中尚未添加前面章节的基础安全规则,实际生产环境应合并所有规则后统一加载):
$ nft list ruleset
table inet filter {
chain input {
type filter hook input priority 0;
}
chain forward {
type filter hook forward priority filter; policy drop;
oifname "docker0" ip daddr 172.17.0.0/16 ct state established,related accept
iifname "docker0" ip saddr 172.17.0.0/16 accept
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table inet nat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
oifname != "docker0" ip daddr != 127.0.0.0/8 masquerade
}
chain DOCKER {
type nat hook prerouting priority dstnat; policy accept;
}
chain DOCKER_OUTPUT {
type nat hook output priority -100; policy accept;
}
}
table ip nat {
chain DOCKER {
iifname != "docker0" meta l4proto tcp tcp dport 5432 counter packets 60 bytes 2844 dnat to 172.17.0.2:5432
}
chain PREROUTING {
type nat hook prerouting priority dstnat; policy accept;
fib daddr type local counter packets 175176 bytes 9571421 jump DOCKER
}
chain OUTPUT {
type nat hook output priority -100; policy accept;
ip daddr != 127.0.0.0/8 fib daddr type local counter packets 27678 bytes 1660680 jump DOCKER
}
chain POSTROUTING {
type nat hook postrouting priority srcnat; policy accept;
oifname != "docker0" ip saddr 172.17.0.0/16 counter packets 0 bytes 0 masquerade
oifname != "br-afdd646856cb" ip saddr 172.18.0.0/16 counter packets 0 bytes 0 masquerade
}
}
table ip filter {
chain DOCKER {
iifname != "docker0" oifname "docker0" meta l4proto tcp ip daddr 172.17.0.2 tcp dport 5432 counter packets 60 bytes 2844 accept
iifname != "br-afdd646856cb" oifname "br-afdd646856cb" counter packets 0 bytes 0 drop
iifname != "docker0" oifname "docker0" counter packets 0 bytes 0 drop
}
chain DOCKER-FORWARD {
counter packets 209 bytes 11180 jump DOCKER-CT
counter packets 209 bytes 11180 jump DOCKER-INTERNAL
counter packets 209 bytes 11180 jump DOCKER-BRIDGE
iifname "br-afdd646856cb" counter packets 0 bytes 0 accept
iifname "docker0" counter packets 0 bytes 0 accept
}
chain DOCKER-BRIDGE {
oifname "br-afdd646856cb" counter packets 0 bytes 0 jump DOCKER
oifname "docker0" counter packets 209 bytes 11180 jump DOCKER
}
chain DOCKER-CT {
oifname "br-afdd646856cb" ct state related,established counter packets 0 bytes 0 accept
oifname "docker0" ct state related,established counter packets 0 bytes 0 accept
}
chain DOCKER-INTERNAL {
}
chain FORWARD {
type filter hook forward priority filter; policy accept;
counter packets 209 bytes 11180 jump DOCKER-USER
counter packets 209 bytes 11180 jump DOCKER-FORWARD
}
chain DOCKER-USER {
}
}
table ip6 nat {
chain DOCKER {
}
chain PREROUTING {
type nat hook prerouting priority dstnat; policy accept;
fib daddr type local counter packets 0 bytes 0 jump DOCKER
}
chain OUTPUT {
type nat hook output priority -100; policy accept;
ip6 daddr != ::1 fib daddr type local counter packets 0 bytes 0 jump DOCKER
}
}
table ip6 filter {
chain DOCKER {
}
chain DOCKER-FORWARD {
counter packets 0 bytes 0 jump DOCKER-CT
counter packets 0 bytes 0 jump DOCKER-INTERNAL
counter packets 0 bytes 0 jump DOCKER-BRIDGE
}
chain DOCKER-BRIDGE {
}
chain DOCKER-CT {
}
chain DOCKER-INTERNAL {
}
chain FORWARD {
type filter hook forward priority filter; policy accept;
counter packets 0 bytes 0 jump DOCKER-USER
counter packets 0 bytes 0 jump DOCKER-FORWARD
}
chain DOCKER-USER {
}
}
table ip raw {
chain PREROUTING {
type filter hook prerouting priority raw; policy accept;
iifname != "docker0" ip daddr 172.17.0.2 counter packets 0 bytes 0 drop
}
}table inet filter + table inet nat
这是我们手动配置的 Docker 兼容规则,包含流量转发、NAT 地址转换,是 Docker 网络正常运行的核心。
剩余所有规则(ip nat/ip filter/ip6 等):这是 Docker 服务自动生成的系统规则,用于管理容器端口映射、网络桥接,无需我们手动编写、修改、维护,Docker 会自动管理。
补充说明: 以上
ip、ip6家族的表(如ip nat、ip filter、ip6 nat、ip6 filter、ip raw等)全部是 Docker 服务启动时自动创建和维护的,它们负责处理容器间的网络桥接、端口转发、安全隔离等底层网络逻辑。我们不需要手动修改这些规则,也不建议删除或调整,重启 Docker 后它们会自动重建。
看到这个输出,就证明 nftables + Docker 已完全兼容,容器可以正常启动、联网、端口映射。
配置完成后记得重启Docker,才会生成相应的Docker转发工具。
🚨 重要细节
如果大家之前启动过一次Docker,加载完Docker的转发之后,后续新增了相关规则,并重新执行,会发现加载完 nftables 配置后,Docker 自动生成的规则表全部消失了。
这是完全正常的现象,原因如下:
我们的配置文件第一行 flush ruleset 会清空服务器所有防火墙规则,Docker 自动生成的规则属于内存临时规则,会被一并清空,所以在新一次加载防火墙规则之后,要重启Docker:
# 1. 加载防火墙配置
nft -f /etc/nftables.conf
# 2. 重启 Docker 自动重建网络规则
systemctl restart docker2.6 端口速率限制
配置完端口放行后,我们还可以给端口加上速率限制,这是服务器安全的重要一环。
简单来说:限制同一个 IP,在单位时间内访问指定端口的最大次数,可以有效防止 SSH 暴力破解、CC 攻击、端口恶意扫描,保护服务器不被流量压垮。
nftables 内置了速率限制模块,我们可以直接配置:
- 允许正常访问
- 拦截短时间内疯狂请求的恶意 IP
- 支持自定义:每分钟 / 每秒允许多少次请求
场景 1:SSH 端口速率限制
这应该是最常用的了,可以有效防止ssh暴力破解,我们优先给 SSH(22 端口)加限制,这是服务器最容易被攻击的端口。
规则示例:同一个 IP,每分钟最多尝试连接 SSH 3 次,超过直接拦截。
# SSH 端口速率限制:每分钟最多3次连接,突发5次(容错)
ip saddr { 1.2.3.4 } tcp dport 22 ct state new limit rate 3/minute burst 5 accept说明: 这条规则仅对白名单 IP 生效。如果你已在 2.2 节配置了 SSH IP 白名单,可以用这条规则替换原来的白名单规则,在允许访问的同时限制白名单 IP 的访问频率,防止内部滥用或账号泄露后的暴力破解。
limit rate 3/minute:核心,每分钟最多允许 3 次新连接。
burst 5:突发流量容错,允许短时间多几次请求,避免正常操作被误拦,仅对白名单 IP 生效,更安全。
场景 2:Web 端口速率限制(防 CC 攻击)
给 80/443 等 Web 端口加限制,防止恶意请求刷爆服务。
规则示例:同一个 IP,每秒最多 20 次请求。
# Web端口速率限制:每秒最多20次请求
tcp dport { 80, 443 } ct state new limit rate 20/second accept场景 3:自定义业务端口速率限制
针对服务器开放的 3000、4096、8088 等自定义业务端口,添加专属限速,避免单个 IP 占用大量资源。
规则示例:单个 IP 每秒最多 10 次新连接
# 自定义业务端口限速
tcp dport { 3000, 4096, 8088 } ct state new limit rate 10/second accept2.7 限制 Ping 请求
Ping 是我们日常测试服务器网络连通性的常用工具,但它也存在安全风险:黑客可能利用 ICMP 洪水攻击(疯狂发送 Ping 请求)消耗服务器资源,也能通过 Ping 扫描判断你的服务器是否在线。
借助 nftables,我们可以灵活管控 Ping 请求:既可以保留正常的 Ping 功能,又限制请求频率;也可以直接禁止 Ping,让服务器在网络中更隐蔽。
小tips:我们使用的 Ping 命令,底层依靠 ICMP 协议传输数据,所以我们只需要针对这个协议配置规则即可。
场景 1:允许 Ping + 速率限制
不影响正常的网络连通性测试,同时拦截恶意高频 Ping,是最实用的方案。
规则示例:同一个 IP,每分钟最多允许发起 10 次 Ping 请求。
chain input {
type filter hook input priority filter; policy drop;
# 限制Ping请求:每分钟最多10次,防止ICMP洪水攻击
ip protocol icmp limit rate 10/minute accept
}ip protocol icmp:匹配 Ping 所使用的 ICMP 协议。
limit rate 10/minute:核心限速,每分钟最多允许 10 次请求。
accept:放行符合频率要求的正常 Ping 请求。
场景 2:完全禁止 Ping 请求
如果你不需要任何人 Ping 你的服务器,可以直接拦截所有 ICMP 请求,让外部无法通过 Ping 探测到服务器。
chain input {
type filter hook input priority filter; policy drop;
# 完全禁止所有Ping请求
ip protocol icmp drop
}drop:直接丢弃所有 Ping 请求,外界 Ping 服务器会显示超时 / 不通。
2.8 IP黑名单配置
如果我们发现有恶意 IP持续攻击、扫描、暴力破解我们的服务器,单纯的速率限制已经不够用了,这时候我们可以直接将其加入IP 黑名单,彻底封禁该 IP 访问服务器的所有权限,这是最直接、最强硬的安全防护手段。
nftables 配置黑名单非常简单,核心规则只有一个:drop(丢弃),支持单个 IP、多个 IP、整个 IP 段批量封禁。
**黑名单规则必须放在 input 链的最顶部!**正如我们在2.4中提到的,nftables 规则是 从上到下 逐行匹配的,只要匹配到了第一条符合条件的规则,立刻执行动作,后面的所有规则直接跳过、不再看。
因为 nftables 规则从上到下匹配,先拦截黑名单 IP,再执行后续的放行、限速规则,否则黑名单会失效。
场景 1:封禁单个恶意 IP
直接封禁某个攻击你的 IP,禁止其访问服务器任何端口(SSH、Web、业务端口全部禁止)。
# 封禁单个恶意IP 192.168.1.100,直接丢弃所有请求
ip saddr 192.168.1.100 drop场景 2:封禁多个恶意 IP
同时封禁多个扫描、攻击 IP,用大括号 + 英文逗号分隔。
# 批量封禁多个恶意IP
ip saddr { 1.2.3.4, 5.6.7.8, 11.22.33.44 } drop场景 3:封禁整个IP 段
如果发现一整个网段都在恶意攻击,可以直接封禁整个网段。
# 封禁整个IP段 123.45.0.0/16
ip saddr 123.45.0.0/16 drop那么完整配合使用:
chain input {
type filter hook input priority filter; policy drop;
# IP黑名单,最顶部,优先执行
ip saddr { 1.2.3.4, 5.6.7.8 } drop
ip saddr { 1.2.3.4, 5.6.7.8, 11.22.33.44 } drop
ip saddr 123.45.0.0/16 drop
# 基础安全规则
iif "lo" accept
ct state established,related accept
ct state invalid drop
# ......
}小提醒:千万不要封禁自己的 IP,否则你会无法连接服务器!黑名单优先级最高,一旦封禁,该 IP 无法访问任何服务;如需解除封禁,删除配置中对应的 IP 规则,重新加载即可。
2.9 IPv6 基础防护
随着服务器网络环境的完善,IPv6 已经成为很多服务器的标配网络协议。和 IPv4 一样,IPv6 也面临着暴力破解、端口扫描、恶意访问等安全风险,我们需要在 nftables 中为 IPv6 配置基础防护,做到IPv4 与 IPv6 双重安全。
IPv4 和 IPv6 是两套完全独立的网络协议,防火墙规则互不通用、互不继承;我们仅配置了 IPv4 的防火墙规则,限制了 80、443、3000 等业务端口的访问权限;由于未配置 IPv6 防火墙规则,IPv6 流量默认不受限制、所有端口均放行,因此纯 IPv6 地址的用户可以正常访问你的网站 / 服务,不会被拦截。
接下来我们先看一个独立配置 IPv6 防火墙规则的示例。不过请注意:由于 inet 族本身同时覆盖 IPv4 和 IPv6 流量,这里单独建一个 filter6 表也会处理 IPv4 流量,表名只是标识符,不会限定协议。所以后面我们会讲更推荐的做法——直接在同一个 inet filter 表中统一管理,这里仅作对比理解使用。
# IPv6 防火墙配置(说明性示例,推荐使用后文的统一方案)
table inet filter6 {
chain input {
type filter hook input priority filter; policy drop;
# 1. 放行本地回环接口
iif "lo" accept
# 2. 放行已建立、相关的连接
ct state established,related accept
# 3. 丢弃无效的数据包
ct state invalid drop
# 4. IPv6 SSH 白名单
# 仅允许信任的 IPv6 地址访问 SSH 端口,按需开启
# ip6 saddr { 240e:xxx:xxx::1/64 } tcp dport 22 ct state new accept
# 5. 放行业务端口
# 示例:放行 Web 端口、自定义业务端口
tcp dport { 80, 443, 3000, 8088 } ct state new accept
# 6. IPv6 Ping 限速
meta l4proto icmpv6 limit rate 10/minute accept
}
# 转发链:保持默认拦截,仅放行必要流量
chain forward {
type filter hook forward priority filter; policy drop;
}
# 出站链:默认放行,保障服务器主动访问网络
chain output {
type filter hook output priority filter; policy accept;
}
}在 nftables 防火墙体系中,inet 是协议家族关键字,代表这张表同时管理 IPv4 和 IPv6 流量,是现代 Linux 系统配置双栈防火墙的核心。
它打破了传统 iptables(仅 IPv4)和 ip6tables(仅 IPv6)协议分离的架构,将两种协议的流量规则整合在同一张表中,实现网络流量过滤规则的集中化管理。
# 你的服务器配置:标准双栈统一表(表名 filter)
table inet filter {
# 入站流量链:管控所有进入服务器的流量
chain input {
type filter hook input priority filter; policy drop;
# 放行本地回环流量
iif lo accept
# 放行已建立连接的流量(保障会话正常通信)
ct state established,related accept
# 丢弃无效的数据包
ct state invalid drop
# 放行网站/业务端口(双协议通用:IPv4+IPv6同时生效)
tcp dport {80, 443, 81, 4096, 3000} ct state new accept
# Ping 限速(防洪水攻击)
ip protocol icmp limit rate 10/minute accept
meta l4proto icmpv6 limit rate 10/minute accept
}
# 转发流量链
chain forward {
type filter hook forward priority filter; policy drop;
}
# 出站流量链
chain output {
type filter hook output priority filter; policy accept;
}
}总结:
规则复用:双协议流量共享同一套规则逻辑,减少重复配置,降低运维成本。
性能更优:nftables 内核原生支持,规则执行效率高于传统的 iptables 组合,在高流量场景下表现更稳定。
适配现代网络:随着 IPv6 网络的普及,table inet filter 成为服务器防火墙的标准配置,完美适配双栈网络环境。
配置灵活:支持分链管理流量(input/forward/output),规则结构清晰,便于后期扩展和维护。
2.10 Docker Compose 多网桥兼容
前面我们讲的 Docker 兼容配置,都是基于默认的 docker0 网桥。但实际生产环境中,如果你使用了 Docker Compose,它会为每个项目自动创建独立的自定义网桥(名称类似 br-afdd646856cb),分配独立的内网网段(如 172.18.0.0/16、172.19.0.0/16 等)。
这时候,我们之前只针对 docker0 写的转发和 NAT 规则,对自定义网桥是不生效的,会导致 Docker Compose 项目中的容器无法联网、端口映射失败。
怎么解决?
我们需要在 forward 链和 nat 表中,为每个自定义网桥添加对应的规则。
第一步:查看你的 Docker 网桥
先确认服务器上有哪些 Docker 网桥,以及它们的网段:
# 查看所有 Docker 网络
docker network ls
# 查看具体网络的网段信息(替换 network_name 为实际名称)
docker network inspect network_name | grep Subnet假设你的 Docker Compose 项目创建了一个网桥 br-afdd646856cb,网段为 172.18.0.0/16。
第二步:补充 forward 链规则
在 forward 链中,为新网桥添加和 docker0 一样的三条规则:
chain forward {
type filter hook forward priority filter; policy drop;
# === 默认网桥 docker0 (172.17.0.0/16)===
iifname != "docker0" oifname "docker0" ct state new accept
oifname "docker0" ip daddr 172.17.0.0/16 ct state established,related accept
iifname "docker0" ip saddr 172.17.0.0/16 accept
# === Docker Compose 自定义网桥(按你的实际网桥名和网段修改)===
iifname != "br-afdd646856cb" oifname "br-afdd646856cb" ct state new accept
oifname "br-afdd646856cb" ip daddr 172.18.0.0/16 ct state established,related accept
iifname "br-afdd646856cb" ip saddr 172.18.0.0/16 accept
}第三步:补充 NAT 表规则
在 nat 表的 postrouting 链中,为新网桥添加 IP 伪装规则:
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
# 默认网桥
oifname != "docker0" ip saddr 172.17.0.0/16 ip daddr != 127.0.0.0/8 masquerade
# Docker Compose 自定义网桥
oifname != "br-afdd646856cb" ip saddr 172.18.0.0/16 ip daddr != 127.0.0.0/8 masquerade
}核心逻辑和 docker0 完全一样,只是把网桥名和网段替换成自定义网络的即可。如果有多个 Docker Compose 项目,就依次添加对应的规则。
小提示: 每次新建 Docker Compose 项目并创建了新的自定义网络后,记得检查防火墙规则是否覆盖了新网桥。如果漏了,该项目的容器就会出现网络不通或端口映射失败的情况。
2.11 流量日志与计数审计
在生产环境中,防火墙不仅要拦得住攻击,还要看得见攻击。nftables 提供了 counter(计数器)和 log(日志)两个工具,帮助我们统计流量数据、记录被拦截的访问,便于安全审计和问题排查。
2.11.1 计数器 counter
counter 可以统计每条规则匹配了多少个数据包、多少字节的流量,是最轻量的审计手段,对性能几乎没有影响。
使用方式非常简单,在任意规则的动作前加上 counter 关键字即可:
chain input {
type filter hook input priority filter; policy drop;
# 统计被丢弃的无效数据包数量
ct state invalid counter drop
# 统计 SSH 白名单的访问次数
ip saddr { 1.2.3.4 } tcp dport 22 ct state new counter accept
# 统计 Web 端口的访问量
tcp dport { 80, 443 } ct state new counter accept
}加载规则后,通过 nft list ruleset 查看,每条带 counter 的规则后面会自动显示统计数据:
$ nft list ruleset
# 输出示例(截取部分)
ct state invalid counter packets 1523 bytes 72816 drop
ip saddr { 1.2.3.4 } tcp dport 22 ct state new counter packets 47 bytes 2820 accept
tcp dport { 80, 443 } ct state new counter packets 18692 bytes 1121520 acceptpackets 1523 表示该规则命中了 1523 个数据包,bytes 72816 表示总流量大小。通过这些数据,你可以清晰地看到:有多少无效包被拦截、SSH 被尝试了多少次、Web 服务承受了多少请求。
2.11.2 日志 log
如果你需要详细记录某类流量的具体信息(来源 IP、目标端口、协议等),可以使用 log 将信息写入系统日志。
chain input {
type filter hook input priority filter; policy drop;
# 记录所有被拦截的入站流量(写入系统日志)
counter log prefix "[nftables-drop] " drop
# 记录可疑的 SSH 尝试
tcp dport 22 ct state new log prefix "[nftables-ssh] " counter accept
}log prefix "[nftables-drop] ":给日志条目加一个前缀标签,方便在系统日志中快速筛选。
日志会写入系统日志文件,通过以下命令查看:
# 实时查看防火墙日志
journalctl -k | grep "nftables"
# 或者查看 syslog
grep "nftables" /var/log/syslog⚠️ 注意:
log在高流量场景下会产生大量日志数据,可能影响磁盘 I/O 和存储空间。建议仅对关键规则启用日志(如被拦截的流量、SSH 尝试),不要对所有规则都加log。日常运维中,counter已经够用,log作为排查问题时的按需开启工具即可。
2.11.3 推荐组合
日常生产环境,推荐以下轻量审计策略:
chain input {
type filter hook input priority filter; policy drop;
iif "lo" accept
ct state established,related accept
# 统计无效包数量(轻量审计)
ct state invalid counter drop
# SSH 白名单 + 计数
ip saddr { 1.2.3.4 } tcp dport 22 ct state new counter accept
# 业务端口 + 计数
tcp dport { 80, 443 } ct state new counter accept
# Ping 限速 + 计数
ip protocol icmp limit rate 10/minute counter accept
}这套配置零性能损耗,随时通过 nft list ruleset 就能看到每条规则的命中情况,是生产环境最实用的审计方式。
2.12 开机自启与持久化
到目前为止,我们所有的防火墙配置,都是通过 nft -f /etc/nftables.conf 手动加载的。但如果服务器重启了怎么办?
答案是:规则会全部丢失,服务器重新回到裸奔状态。
因为 nftables 的规则是加载到内核内存中的,服务器重启后内存被清空,规则自然就没了。所以我们必须配置开机自动加载防火墙规则,确保服务器在任何情况下重启后,防火墙都能自动生效。
2.12.1 确认配置文件路径
确保你的防火墙规则已经完整写入 /etc/nftables.conf,这是 nftables 服务默认读取的配置文件。
# 验证配置文件语法是否正确(不会实际加载,只做语法检查)
nft -c -f /etc/nftables.conf如果没有任何输出,说明语法正确;如果报错,需要先修正配置文件。
2.12.2 启用 nftables 系统服务
Ubuntu 系统自带 nftables 的 systemd 服务单元,我们只需要启用它:
# 设置 nftables 开机自启
systemctl enable nftables
# 立即启动服务(加载配置文件中的规则)
systemctl start nftables
# 查看服务状态,确认正常运行
systemctl status nftables执行 systemctl enable nftables 后,系统会在每次开机时自动执行 /etc/nftables.conf,加载防火墙规则。
2.12.3 验证持久化效果
配置完成后,建议通过以下步骤验证:
# 1. 确认当前规则已生效
nft list ruleset
# 2. 重启服务器
reboot
# 3. 重启后重新登录,再次检查规则是否自动加载
nft list ruleset如果重启后 nft list ruleset 能看到完整的防火墙规则,说明持久化配置成功。
2.12.4 完整的规则更新流程
日后每次修改防火墙规则,推荐按以下标准流程操作:
# 1. 编辑配置文件
vim /etc/nftables.conf
# 2. 语法检查(养成好习惯,避免加载错误的配置导致断连)
nft -c -f /etc/nftables.conf
# 3. 加载新规则
nft -f /etc/nftables.conf
# 4. 如果有 Docker,重启 Docker 重建网络规则
systemctl restart docker
# 5. 验证规则生效
nft list ruleset⚠️ 特别注意: 语法检查这一步非常重要!如果配置文件有语法错误,直接加载可能导致
flush ruleset执行成功(清空所有规则),但新规则加载失败,服务器瞬间变成无防火墙状态。先用-c参数检查,确认无误后再加载,这是生产环境的铁律。
三、总结
在公网直连、无安全组防护的 Ubuntu 22.04 服务器上,搭配 Docker 容器使用时,我们基于 nftables 打造了一套极简高性能的防火墙方案。不依赖云厂商防护工具,仅依靠系统自身能力,彻底解决服务器直面公网的安全风险,适配轻量服务器的硬件特性,零额外性能损耗。
从基础安全加固到 Docker 网络兼容(包括 Docker Compose 多网桥场景),从 SSH 防护到端口限流,从流量审计到开机持久化,我们从零落地全流程配置,打造生产可用的防火墙体系,让裸奔服务器获得专业级安全防护,兼顾安全、稳定与运维便捷性。
附、运维命令
# 1. 加载防火墙规则(修改配置后必执行,立即生效)
nft -f /etc/nftables.conf
# 2. 加载前语法检查(强烈推荐,避免加载失败导致防火墙失效)
nft -c -f /etc/nftables.conf
# 3. 查看当前所有生效的防火墙规则
nft list ruleset
# 4. 查看带 handle 编号的规则(删除规则时使用)
nft -a list ruleset
# 5. 设置 nftables 开机自启(服务器重启后自动生效)
systemctl enable nftables
# 6. 启动 / 查看 nftables 服务状态
systemctl start nftables
systemctl status nftables
# 7. 重启 Docker(加载防火墙规则后必执行,修复容器网络)
systemctl restart docker
# 8. 查看 Docker 网桥和网段(配置多网桥兼容时使用)
docker network ls
docker network inspect <网络名称> | grep Subnet
# 9. 查看防火墙日志(配合 log 规则使用)
journalctl -k | grep "nftables"
grep "nftables" /var/log/syslog
# 10. 临时清空所有防火墙规则(紧急救急使用)
nft flush ruleset
# 11. 查看服务器对外开放端口(验证防护效果)
ss -tuln
netstat -lnpt本人示例
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
type filter hook input priority filter; policy drop;
iif "lo" accept
ct state established,related accept
ct state invalid counter drop
ip saddr { 1.2.3.4 } tcp dport 22 ct state new limit rate 3/minute burst 5 packets counter accept
tcp dport { 80, 443 } ct state new limit rate 20/second burst 40 packets counter accept
ip protocol icmp limit rate 10/minute counter accept
meta l4proto icmpv6 limit rate 10/minute counter accept
}
chain forward {
type filter hook forward priority filter; policy drop;
iifname != "docker0" oifname "docker0" ct state new accept
oifname "docker0" ip daddr 172.17.0.0/16 ct state established,related accept
iifname "docker0" ip saddr 172.17.0.0/16 accept
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table inet nat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
oifname != "docker0" ip saddr 172.17.0.0/16 ip daddr != 127.0.0.0/8 masquerade
}
chain DOCKER {
type nat hook prerouting priority dstnat; policy accept;
}
chain DOCKER_OUTPUT {
type nat hook output priority -100; policy accept;
}
}
评论
游客无需注册即可评论。
你提交的昵称、邮箱、网址和评论内容会保存在服务端,用于展示评论身份、接收回复及必要的安全审计。
浏览器会本地保存已填游客信息和评论草稿,方便下次免填。
回复提醒会通过站内消息和邮件通知。